2nd_edition_bigdataplatform_and_engineering
改訂新版[エンジニアのための]データ分析基盤入門<基本編> データ活用を促進する! プラットフォーム&データ品質の考え方
本リポジトリは、技術評論社から出版された以下の書籍 のWeb補足情報を提供するためのものです。 書籍に関する「正誤表」や関連情報をまとめています。

- title : 改訂新版[エンジニアのための]データ分析基盤入門<基本編> データ活用を促進する! プラットフォーム&データ品質の考え方
- Publisher : 技術評論社 (Nov. 5, 2024)
- Publication date : Nov. 5, 2024
- Language : Japanese
- Tankobon Softcover : 368 pages
- ISBN-10 : 4297145634
- ISBN-13 : 978-4297145637
本書の構成
各章のハイライトです。
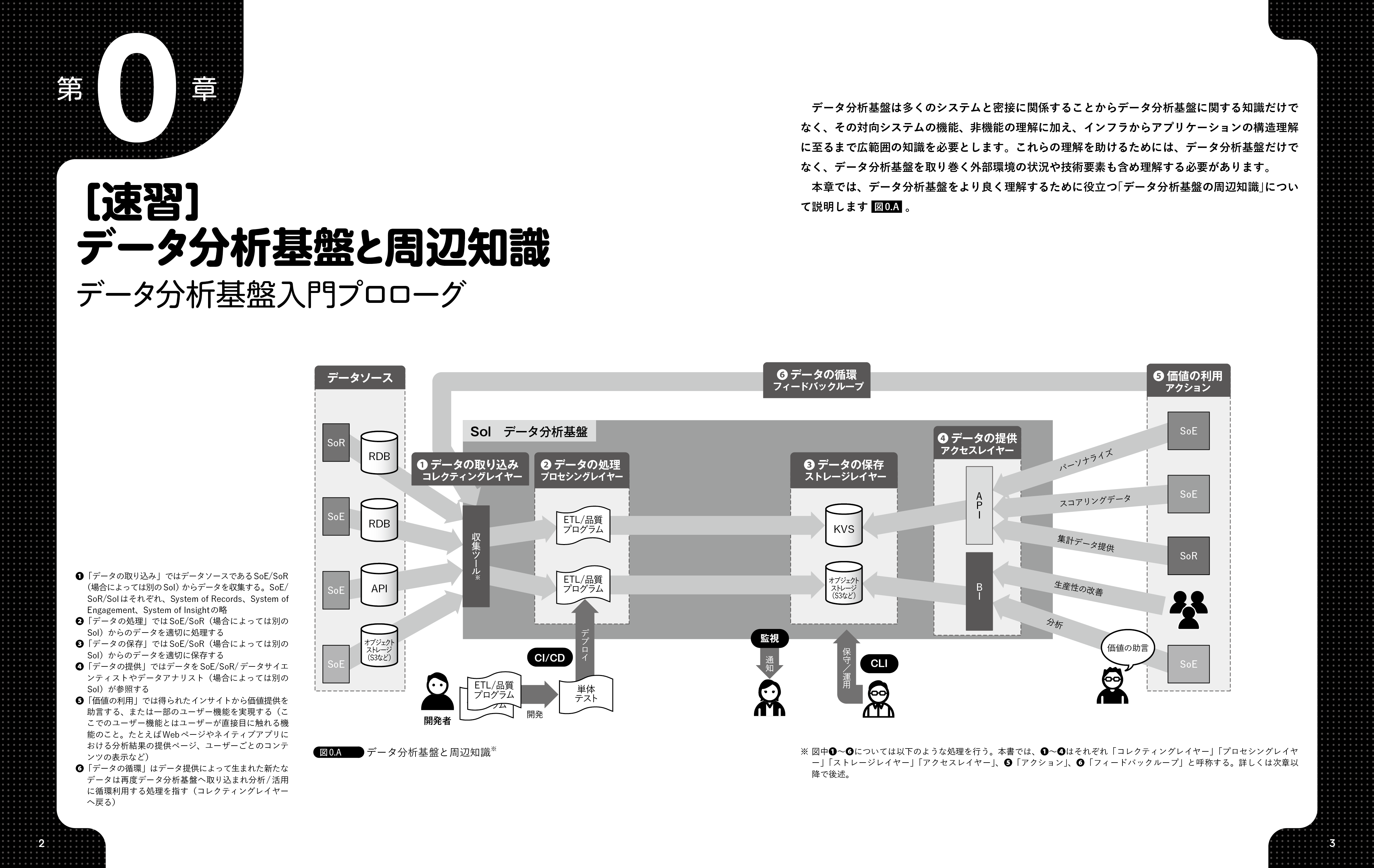
第0章 [速習]データ分析基盤と周辺知識 データ分析基盤入門プロローグ 本書を読みやすくするために基本的な技術や既存の知識とデータ分析基盤関連の技術へのつなぎ込みを行 う章です。
第1章 [入門]データ分析基盤 データ分析基盤を取り巻く「人」「技術」「環境」 ビッグデータの歴史や現状を紹介します。はじめに、ビッグデータ世界の概略を押さえておきましょう。
第2章 データエンジニアリングの基礎知識 4つのレイヤー データ分析基盤を管理する「データエンジニアリング」を想定して、職責やナレッジを含めた基礎知識を概 説します。データエンジニアリングでカバーすべき範囲は多岐にわたるため、まずは大まかにデータ分析基 盤全体を把握していきましょう。
第3章 データ分析基盤の管理&構築 セルフサービス、SSoT、タグ、ゾーン、メタデータ管理 データ分析基盤を構築/管理する上で大切なポイントである「セルフサービス」「SSoT」(Single source of truth) という考え方を中心によりビジネス成果を創出しやすいデータ分析基盤に求められる役割や考え方、方法論 について解説します。
第4章 データ分析基盤の技術スタック データソースからアクセスレイヤー、クラスター、ワークフローエンジンまで データ分析基盤を4つの層に分割し、それぞれの層で登場する技術スタックを紹介します。 ユーザーがデータを利用した成果の創出に集中するためのベースとなる特定の技術スタックを取り上げて、 特徴や用途を説明します。多々あるビッグデータの技術の中から、必要性を見極めて技術選択できるように なることを目指します。
第5章 メタデータ管理 データを管理する「データ」の重要性 データを管理するためのメタデータを紹介します。「データの定義をSQLで都度調べている」「データが見つけづ らい」「データが活用されない」などデータ分析基盤のユーザーの悩みを、メタデータを通して解決していきましょう。
第6章 データマート&データウェアハウスとデータ整備 DIKWモデル、データ設計、スキーマ設計、最小限のルール データマートを作成し綺麗に整形することも大事ですが、単純な作成方法だけにとどまらず、ユーザーが データマートを自由に素早く反復して作成できるようにすることが重要です。 データ利用の一つの障壁となる人とのコミュニケーションをシンプルにするための方法についても紹介します。
第7章 データ品質管理 質の高いデータを提供する データの状態を常にモニタリングすることで、データの精度を高めるデータ品質管理について説明します。 間違えたデータで意思決定をしないように、データの品質を継続的に測定し、データの設計書を残し継続的 に成果の創出できるデータ分析基盤を作り上げます。
第8章 データ分析基盤から始まるデータドリブン データ分析基盤の可視化&測定 データ分析基盤開発の方向を見失わないようにするために、KPI管理とKPI管理対象項目について紹介し ます。実際のデータ分析基盤の管理/運用で活用できる項目を重点的に取り上げます。
第9章 [事例で考える]データ分析 基盤のアーキテクチャ設計 豊富な知識と柔軟な思考で最適解を目指そう 本書の知識整理を目的として、第0章〜第8章までの知識を利用して、シンプルなユースケースを元にデ ータ分析基盤の設計に取り組みます。サンプルコード付きです。
Appendix [ビッグデータでも役立つ]RDB基礎講座 ビッグデータに関する技術要素は、リレーショナルデータベース(relational database、RDB)の技術要素と通 ずるものがあります。第1章からの本編解説の理解の助けになるように、RDBの基本を解説します。
本書で登場するCodes
本書で登場するサンプルコードは以下に配置しております。
正誤表
初版修正情報
(紙版のみ)0章のトップ画が見開きの間に入ってしまい見辛くなっている
こちらが全体像となります。
 また
CI/CDI となっていますが -> CI/CDが正となります。
また
CI/CDI となっていますが -> CI/CDが正となります。
サードパーティより、セカンドパーティーの方がコンテキスト的に伝わりやすい部分の修正
- (p8の注釈): 協業先のサードパーティデータや -> 、協業先のセカンドパーティデータや
- (p36のTips): セカンドパーティーデータ(業務協業元からのデータ)
- (p72) :❶ではサードパーティのデータソースから -> 、 ❶ではセカンドパーティのデータソースから
- (p319):サードパーティ企業とのデータ連携などでプロジェクトを進 -> サードパーティやセカンドパーティ企業とのデータ連携などでプロジェクトを進
p176(クラスターキー。。。低すぎると、ホットスポット問題の発生要因となり)
クラスターキーはホットスポットの主要因として成り立たないため、この一文を削除
p176(カーディナリティが高すぎると並び替えの意義が薄くなる)
カーディナリティではなく、「時系列と無関係にユニーク化されたキー(例:ランダムな UUID)」をソート(クラスタ)キーとして採用するケース」だと並び替えの意義が薄くなります。
誤字/脱字
- (p127): DELTA LAKES -> DELTA LAKE
- (p241): 前者のViewを使ったPECA」とありますが -> PDCAの間違え
- (p230): 最終行11台-> 11時台
- (p307): 「Amazon AuickSight」->「Amazon QuickSight」
本書内で紹介している書籍や参考情報
ここではビッグデータ関連書籍として、書籍内で紹介している書籍やおすすめの書籍について紹介します。
図書
- Spark: The Definitive Guide: Big Data Processing Made Simple (English Edition)
- Kafka: The Definitive Guide (English Edition)
- データ指向アプリケーションデザイン ―信頼性、拡張性、保守性の高い分散システム設計の原理
- データエンジニアリングの基礎 ―データプロジェクトで失敗しないために
- ZooKeeperによる分散システム管理
リファレンス
筆者が図表等を作成する際に参考とさせていただいたドキュメント群です。
セマンティックレイヤーの解説(図表等の作成)の際に参考にさせていただきました。
本文で言及しているDBT公式を元に以下の情報も参考にさせていただいております。
- セマンティックレイヤー / Headless BIとは
- DevelopersIO 2023でコードでデータ分析に関わる指標を管理できる「Semantic Layer」についてLookerとdbtの違いを話しました #devio2023
- 生成AIを活用するデータ民主化、セマンティックレイヤーで支えるBI「Looker」
- ビジネス職のためのデータ基盤入門:セマンティックレイヤーの紹介
- https://dev.classmethod.jp/articles/tableau-connect-to-dbt-semantic-layer/
動作環境
本書を作成時に利用した筆者の動作の確認環境は以下です。
-(ローカル環境)MacBook Pro(M1 Max, 2021)
- Docker Desktop 4.34.2(167172)
- Python 3.12.4
- Java 8(Embulkで利用) / Java17(Embulk以外, 17.0.12)
- Spark 3.5.3 ※第9章(クラウド環境)ではGlue 4.0(Spark 3.2)、Glue 4.0/Python shell(Python 3.9)を使用
著者について
普段はデータを活用する企画業務に従事
ビッグデータのシステム構築から活用までアドバイザリーをやっています。
- X(Twitter):@yuki_saito_en
- LinkedIn: https://www.linkedin.com/in/yuki-saito-40872b217/
- Note: https://note.com/yukinkoyuki
- MENTA(アドバイザリー):https://menta.work/member/dashboard
- Udemy(オンライン講師): https://www.udemy.com/user/yuki-saito-7/
その他補助になると考えられるもの
本書で頻繁に出てくるSpark(Pyspark)やKafka、メタデータストア、ストリーミングをコード中心に駆け回ってみる講座たちです。
コードはGithubに公開していますので更に理解を深めるためにご利用ください。
ビジネスパーソン向け他のコース
- 「DX(デジタルトランスフォーメーション)のためのビッグデータ活用とデータ活用企画のつくりかたまで」
- 「【実戦で学ぶ速習講座】リレーショナルデータベースで始めるデータ活用とデータ分析のためのSQLを学ぼう」
エンジニア向け他のコース情報
- 「データサイエンスのための前処理入門PythonとSparkで学ぶビッグデータエンジニアリング(PySpark) 速習講座」
- 「【PythonとSparkで始めるデータマネジメント入門】 ビッグデータレイクのための統合メタデータ管理入門」
- 「【データサイエンスのためのストリーミング前処理入門 PythonとSparkで始めるビッグデータストリーミング処理入門」
- 「超速入門!【データサイエンスへの最初の一歩】PythonとSparkで学ぶデータ分析のための前処理と分散処理 一気見講座」
- 「【実戦で学ぶデータ分析基盤構築講座】ローカル端末で1から始めるデータ分析基盤の構築とデータ活用のための活動」
- 「【実戦で学ぶ基盤構築】ローカル端末で作り理解するエンジニアのための機械学習基盤の作成とMLOps」